TrainTestExtractor Tutorial
Extraction means extracting types within documents (such as names or places). TrainTestExtractor tasks take text data as input. For this example we will use sample1.train as the training data and sample1.test as the testing data. These samples are built into the code, so they require no additional setup. To see how to label and load your own data for this task, look at the Labeling and Loading Data Tutorial.
This experiment will train on one set of data and test on another set. The test set is determined either by specifying test data or by splitting the data. The experiment outputs statistics on token and span precision, recall, and error rates.
- To run this type of task using the GUI do:
$ java –Xmx500M edu.cmu.minorthird.ui.TrainTestExtractor -gui-
A window will appear. To view and change the parameters of the experiment press the
Editbutton located next toTrainTestExtractor. AProperty Editorwill appear:
-
To view what each parameter does and/or how to set it, click the
?button next to each field. The parameters that must be entered for the experiment to run arebaseParameters(-labels) andsignalParameters(-spanTypeor–spanProp). All other parameters have defaults or are not required. There are 5 bunches of parameters that can be modified for running aTrainTestExtractorexperiment:
-
First training data for the experiment must be entered by specifying a
labelsFilename. Since the samples are built into the code,sample1.traincan simply be typed into the text field underlabelsFilenameto load the data. Note: data from a directory can be loaded by using theBrowsebutton. -
To save the results from the experiment, enter a file to which to write the results in the
saveAstext field. Note: this is optional. -
Once
labelsFilenameis specified, click theEditbutton next tosignalParamters. Important:labelsFilenamemust be specified BEFORE clickingEdit. AnotherProperty Editorwill appear. SelecttrueNamefrom the pull down menu. Then press theOKbutton to closeProperty Editor for signalParameters:
-
Type
sample1.testin thetestFilenametext field. Note: when a test file is specified, MinorThird does not use a splitter. To use a splitter, simply do not specify any test file. The splitter is set toRandomSplitterby default thus does not need to be specified or changed for the experiment to run. -
Options for how MinorThird learns from the training data are in
trainingParameters. These options all have defaults, so do not need to be explicitly stated for the experiment to run. Most importantly, the learner can be changed by selected a learner from the pull down menu and edited by pressing theEditbutton next tolearner. To view the Javadoc documentation for the currently selected learner, press the?button for a link to its Javadoc. Theoutputparameter specifies how MinorThird labels extracted types. By default it is set to_prediction, but it is useful to change this to something more informative such aspredicted_trueName.
- Feel free to try changing any of the other parameters including the ones in
advanced options. Click on the help buttons to get a feeling for what each parameter does and how changing it may affect your results. Once all the parameters are set, click theOKbutton inProperty Editor. - Press the
Show Labelsbutton if you would like to view the input data for the extraction task. This will pop up the sameTextBaseViewerthat you would see if you ranViewLabelson the train data. - Now press
Start Taskunder execution controls. The task will vary in the amount of time it takes depending on the size of the data set and what learner and splitter was chosen, but extraction tasks usually take a minute or two. When the task is finished, the error rates will appear in the output text area along with the total time it took to run the experiment. - Now that the experiment has run, the results can be seen. To look at the details of your results, click the
View Resultsbutton in theExecution Controlssection. Click on theEvaluationtab to see the precision rates of the experiment. UnlessshowTestDetailshas been deselected (in theadvancedOptionsmenu of splitter parameters), there will be aFull Test Settab. When this tab is selected, one can compare whatever is labeled (in this case name) to what the learner predicted. When comparing, green means true positive, blue means false negative, and yellow means false positive. You can also click on thespanTypestab and select a color and a spam type to highlight. Make sure that you reset controls before highlighting or comparing. After making a selection, clickApplyto see the result.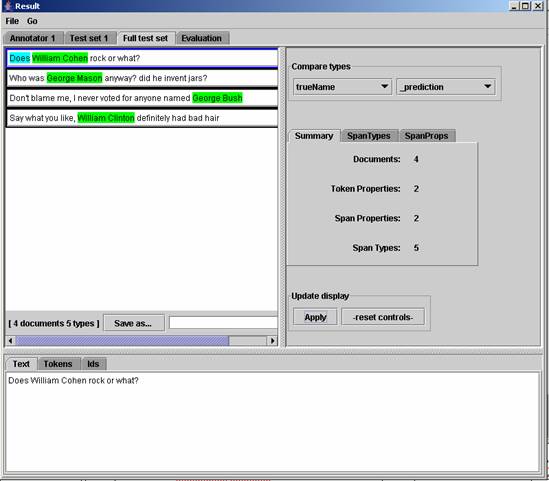
- To view the precision rates of the experiment, click the
Evaluationtab at the top of the window.
-
Precision- # units predicted correctly / # units predicted -
Recall- # of units predicted correctly / # total units -
F1- overall evaluation of performance
- Press the
Clear Windowbutton to clear all output from the output and error messages window. This is useful if you would like to run another experiment.
- To get started using the command line for an extractor experiment do:
$ java –Xmx500M edu.cmu.minorthird.ui.TrainTestExtractor –helpNote: You can enter as many command line arguments as you like along with the –gui argument. This way you can use the command line to specify the parameters that you would like and use and use the GUI to set any additional parameters or view the results.
2. Show options: specifying these options allow one to pop up informative windows from the command line:
-
-showData– interactively show the dataset in a new window -
-showLabels– view the training data and its labels -
-showResult– displays the experiment result in a new window
- The first thing you probably want to enter on the command line is the data you would like to train or train/test on. To do this type
–labelsand the repository key of the dataset you would like to use. For this experiment you should use–labels sample1.train. - Now you either want to specify the dataset you would like to test on by typing
–test testFilenameor specify which splitter you would like to use (this is for when you want to train and test on the same data set). To specify the splitter, type–splitter SPLITTER. Here we are using fixed training and testing data so you can use:–test sample1.test. - The next necessary parameter to name is either
spanProporspanType. To specify this parameter, type–spanType TYPE. For this datasetTYPEcan either be real or spam; here use:-spanType trueName. - Other parameters you may want to specify are:
-
-learnerfor specifying the learning algorithm -
-saveAsif you want to save the trained results -
–helpfor descriptions and examples of options and parameters. If you are unsure of what learners to use, use the–guicommand so that you can see the list of learners and feature extractor available (undertrainingParameters). For this tutorial, use:
-learner "new VPHMMLearner(new CollinsPerceptronLearner(1,5), new Recommended.TokenFE(), new InsideOutsideRedution())"
- As you can see from this example, the
sequenceClassifierLearner,spanFeatureExtractor, andtaggingReductionare defined with the learner. If you would like to see the options for these variables, use the–guicommand. Once the parameter modification window pops up, clickEditunderParameter Modificationand clickEditnext totrainingParameters. To see what learners are available, scroll through the pull down list next to learner. Once you have chosen a learner, click theEditbutton next to learner to choose yoursequenceClassifierLearner,spanFeatureExtractor, andtaggingReduction. To edit any of these training parameters, press theEditbutton next to them. - Optional parameters to define include
–mixup,-embed, and–output. Use the–helpcommand to learn more about these parameters.–outputis set to the default_prediction, so you only need to set this parameter if you would like to name the property learned. - Specify other complex parameters on the command line using the
–otheroption. See the Command Line Other Option Tutorial for details.