There are three kinds of files to edit in OBO explained in the following:
+
+
The normal OBA edit file (src/ontology/obo-edit.obo)
+
The OBA SSSOM mappings (src/mappings/*)
+
The OBA DOSDP pattern files (src/patterns/data/default/*)
+
+
The OBA edit file
+
As opposed to other ontologies, the OBA edit file (src/ontology/obo-edit.obo) is barely used. Power curators will use the oba-edit.obo file occasionally to edit the class hierarchy, but as per OBA principles, the class hierarchy is mostly created by reasoning. Most of OBA editing happens by editing the DOSDP templates, see below.
+
The OBA SSSOM mappings
+
+
OBA-VT SSSOM Mapping: The official mappings between OBA and VT. Source of truth is on Google Sheets, not Github.
+
OBA-EFO SSSOM Mapping: The official mappings between OBA and EFO. Source of truth is on Google Sheets, not Github.
+
OBA-EFO Excluded Mapping: Terms from EFO that have been reviewed and deemed out of scope for OBA. Source of truth is on Google Sheets, not Github.
+
OBA-VT Excluded Mapping: Terms from EFO that have been reviewed and deemed out of scope for OBA. Source of truth is on Google Sheets, not Github.
DOSDP tables are the main way to edit OBA. You can edit the DOSDP TSV files using a regular text editor or a spreadsheet editor.
+
The main rule is, make sure to review the diff before making a pull request - the diff should only show the things you have actually changed.
+
Updating SSSOM mapping files
+
cd src/ontology
+sh run.sh make sync_sssom_google_sheets
+
+
Creating/updating terms
+
+
Preparing alignment work
+
+
Update the data required for the alignment: sh run.sh make prepare_oba_alignment -B. This will take a while, as a lot of ontologies are downloaded and syncronised.
+
Start jupyter in your local environment
+
Open src/scripts/oba_alignment.ipynb in your Jupyter environment and run all over night.
+
While the above is running, read everything in the notebook carefully to get a sense what the notebook is doing. The methods section can be skipped during the first read through, but it will likely be necessary to review these in later stages of the alignment process.
+
The notebook run will produce the following files:
+
src/mappings/oba-vt-unreviewed.sssom.tsv: VT mappings identified by pipeline but not reviewed
+
src/mappings/oba-vt-missed.sssom.tsv: VT mappings identified by looking at OBA IRIs (no need for review)
+
src/mappings/oba-vt-unmapped.sssom.tsv: VT terms that have not been mapped so far (excluding reviewed and candidate mappings)
+
src/mappings/oba-vt-unreviewed.dosdp.tsv: VT terms with candidate DOSDP pattern fillings.
+
src/mappings/oba-efo-unreviewed.sssom.tsv: see above vt analog
+
src/mappings/oba-efo-unmapped.sssom.tsv: see above vt analog
+
src/mappings/oba-efo-unreviewed.dosdp.tsv: see above vt analog
The central pieces for the EFO alignment, if of interest, can be found in the section starting with OBA-EFO Alignment in src/scripts/oba_alignment.ipynb.
+
Review src/mappings/oba-efo-unreviewed.sssom.tsv. These are the new mapping suggestions as determined by the mapping pipeline. Review mappings 1 x 1 and copy them into the official EFO-OBA SSSOM mapping curated on Google Sheets.
+
Review src/mappings/oba-efo-unreviewed.dosdp.tsv. This is the hardest part. The table only provides a handful of suggests on how to map the label using DOSDP. You will have to go through the table subject_id by subject_id and identify the correct corresponding DOSDP pattern tables. Important: when you create an ID (defined_class column DOSDP table) for an EFO-sourced class, you have to add a respective mapping to the official EFO-OBA SSSOM mapping curated on Google Sheets.
+
Optional: Review src/mappings/oba-efo-unmapped.sssom.tsv to figure out what to do about entirely unmapped EFO terms. These may need some careful planning and adjustments of the alignment code.
The central pieces for the EFO alignment, if of interest, can be found in the section starting with OBA-VT Alignment in src/scripts/oba_alignment.ipynb.
+
Review src/mappings/oba-vt-missed.sssom.tsv. This should ideally be empty - these are mappings that have not been factored into the official oba-vt mappings yet, but have the VT-style IRI (OBA:VT0010108) which suggests that the class was derived from the respective VT id. Add all mappings in oba-vt-missed.sssom.tsv to the official VT-OBA SSSOM mapping curated on Google Sheets.
+
Review src/mappings/oba-vt-unreviewed.sssom.tsv. These are the new mapping suggestions as determined by the mapping pipeline. Review mappings 1 x 1 and copy them into the official VT-OBA SSSOM mapping curated on Google Sheets.
+
Review src/mappings/oba-vt-unreviewed.dosdp.tsv. This is the hardest part. The table only provides a handful of suggests on how to map the label using DOSDP. You will have to go through the table subject_id by subject_id and identify the correct corresponding DOSDP pattern tables. Important: when you create an ID (defined_class column DOSDP table) for a VT-sourced class, you add a special IRI that looks like OBA:VT123. This way, mappings will be curated automatically by the framework and you dont have to add them manually.
+
Optional: Review src/mappings/oba-vt-unmapped.sssom.tsv to figure out what to do about entirely unmapped VT terms. These may need some careful planning and adjustments of the alignment code.
Run sh run.sh make sync_templates_google_sheets to sync templates from Google sheets
+
Convince yourself in your favourite git diff tool (GitHub Desktop!) that the changed tables look as intended!
+
In your terminal, run sh run.sh make recreate-measured_in
+
When completed, the file src/ontology/components/measured_in.owl should have been updated. Look at the diff again to convince yourself that the changes look as intended. You may want to open oba-edit.obo in Protege to look at one or two changes!
+
Make sure you are on your new branch created above and commit changes to branch.
+
Publish branch (push to GitHub), make pull request, assign reviewer.
+
+
Adding synonym
+
+
Follow the instructions for adding "measured in" annotations above, except:
Instead of sh run.sh make recreate-measured_in, sh run.sh make recreate-synonyms
+
+
Importing terms and updating DOSDP patterns
+
When creating new OBA terms using DOSDP patterns for example the entity-attribute pattern, it may be necessary to import terms from other ontologies like CHEBI or PRO, the PRotein Ontology. However, CHEBI, NCBITAXON and PRO are too large to be managed easily as standard imports. To mitigate this situation, they can be managed as slims which are located here:
+* NCBITAXON: https://github.com/obophenotype/ncbitaxon/tree/master/subsets
+* PRO: https://github.com/obophenotype/pro_obo_slim
+* CHEBI: https://github.com/obophenotype/chebi_obo_slim
+
Sometimes, a new term you are using in a DOSDP pattern is not yet in a slim. So you will have to refresh the slim first.
+
Refresh LIPID Maps
+
LIPID map is currently (03.06.2023) not imported, but curated manually, because https://www.lipidmaps.org/resources/sparql does not work. To update the LIPID maps imports, you have to
+
+
Add a LIPID term to https://github.com/obophenotype/bio-attribute-ontology/blob/master/src/templates/external.tsv
+
When refreshing the imports in the usual way, this TSV file (a ROBOT template) is built in place of a proper LIPID MAPS mirror.
+
+
Refresh PRO Slim:
+
Note: you will need at least 32 GB RAM for this
+
git clone https://github.com/obophenotype/pro_obo_slim
+cd pro_obo_slim
+git checkout -b refresh20230312
+# Add your terms to seed.txt, and then SORT THE FILE and check that there are no duplicated terms.
+# Make sure that DOCKER is running. To set up DOCKER refer to https://oboacademy.github.io/obook/howto/odk-setup/
+sh odk.sh make all
+git commit -a -m "refresh slim after adding terms for OBA"
+git push --set-upstream origin refresh20230312
+
+
When this is done, make a pull request.
+
Refresh CHEBI Slim
+
git clone https://github.com/obophenotype/chebi_obo_slim
+cd chebi_obo_slim
+# Follow the instructions for the PRO slim from here.
+
+
The full process of refreshing the DOSDP patterns:
+1. Check if new PRO / Chebi terms are not in slim, if they are not, add them as described above.
+2. Run sh run.sh make IMP=false MIR=false ../patterns/definitions.owl to generate a new pattern ontology component.
+3. Run sh run.sh make refresh-merged to import the new terms.
+4. Run sh run.sh make IMP=false MIR=false ../patterns/definitions.owl again to generate the labels correctly where new terms are concerned.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/history/index.html b/history/index.html
new file mode 100644
index 00000000..5283e189
--- /dev/null
+++ b/history/index.html
@@ -0,0 +1,746 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ A brief history of OBA - Ontology of Biological Attributes (OBA)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
How to add new GWAS requested trait terms to OBA and EFO?
+
1. Check if an appropriate OBA trait pattern already exists
+
Look into bio-attribute-ontology/src/patterns/dosdp-patterns/ and check if the GWAS trait term would fit into any of the existing patterns.
+- [ ] If yes, skip to the next step.
+- [ ] If none of the existing OBA trait patterns look appropriate, then create a new pattern.
+In some cases, the requested GWAS term may not fit the scope of OBA. In that case, an new EFO term can be created without an equivalent OBA trait term.
For example, for a trait involving the 'age at which disease manifestations first appear', fill in the table disease_onset.tsv..
+Create a unique OBA identifier by using the next available ID from your assigned range.
+
Also fill in the appropriate columns for the variable fields as specified in the actual DOS-DP yaml template file.
+For example, in the case of the disease_onset.tsv. table, you must use MONDO disease or disorder terms in the disease column.
+
NOTE: Keep track of the IDs from your range that you have already assigned.
+
+
Create a pull request (PR) with the edits. Request other people to review your PR.
+
If approved, merge the PR after the review(s) into the 'master' branch.
+
+
3. OBA release
+
The newly created trait terms can be imported into EFO from a publicly released version of OBA.
[ ] Add the newly created OBA term IRI and also all its component term IRIs to oba_terms.txt so that they get included in EFO dynamic imports. By component terms I mean all those terms that are used in the DOS-DP data filler table to compose the OBA term (terms from MONDO, UBERON, PATO, etc.) as specified in the corresponding DOS-DP pattern file.
Release Workflow for the Ontology of Biological Attributes (OBA)
+
+
Make sure you have the latest ODK installed by running docker:
+
+
docker pull obolibrary/odkfull
+
+
+
Merge as many open PRs as possible.
+
Start with a fresh copy of the master branch. For the next steps you can use GitHub Desktop or the command line instructions below.
+
+
git pull
+
+
Create a new branch:
+
git checkout -b release-202X-XX-XX
+
+
In a terminal window, start the release pipeline:
+
sh run.sh make prepare_release_fast
+
+
NOTE: It is recommended that running the release pipeline is uncoupled from refreshing imports. However, inn case you need to refresh all the imports, you can achieve that by:
+
sh run.sh make prepare_release -B
+
+
+
If everything went all right, you should see message similar to the one below in your terminal window:
+
+
+
...
+Release files are now in ../.. - now you should commit, push and make a release on your git hosting site such as GitHub or GitLab
+make[1]: Leaving directory '/work/src/ontology'
+Please remember to update your ODK image from time to time: https://oboacademy.github.io/obook/howto/odk-update/.
+
+
Check and package the release artefacts for OBA
+
+
You should also check in Protege if the new terms you just added look fine.
+
+
Open in Protege some of the OBA release artefacts and check for any potential errors.
+For example, check if there are any unsatisfiable classes in oba.obo.
+
+
+
Create a pull request and get another pair of eyes to review it.
+
+
Merge your release-202X-XX-XX branch into the master branch once approved by a reviewer and all the automatic quality control checks passed.
+
+
Make a release and include all the release files (including oba-base.owl and oba.obo) as binary files
There should be 15 recently modified files in the root directory of the local copy of the repo:
+
+
oba-base.json
+
oba-base.obo
+
oba-base.owl
+
oba-baseplus.json
+
oba-baseplus.obo
+
oba-baseplus.owl
+
oba-basic.json
+
oba-basic.obo
+
oba-basic.owl
+
oba-full.json
+
oba-full.obo
+
oba-full.owl
+
oba.json
+
oba.obo
+
oba.owl
+
+
+
+
NOTE: GitHub imposes size constraints on repositories. The combined size of the OBA artefacts exceeds the GitHub imposed size limit. For this reason, some of the large release artefact files are not under GitHub version control. However, all the 15 files need to be included in the public release as binary files. For background information on release artefacts, see
Click Draft a new release.
+Click Chose a tag, and create a new tag based on the date on which your ontologies were build. You can find this, for example, by looking into the oba.obo file and checking the data-version: property. The date needs to be prefixed with a v, so, for example v2022-10-17.
+
For the title, you can use the date of the ontology build again, for example 2022-10-17 release
Introduction to Continuous Integration Workflows with ODK
+
Historically, most repos have been using Travis CI for continuous integration testing and building, but due to
+runtime restrictions, we recently switched a lot of our repos to GitHub actions. You can set up your repo with CI by adding
+this to your configuration file (src/ontology/oba-odk.yaml):
+
ci:
+ - github_actions
+
+
When updateing your repo, you will notice a new file being added: .github/workflows/qc.yml.
+
This file contains your CI logic, so if you need to change, or add anything, this is the place!
+
Alternatively, if your repo is in GitLab instead of GitHub, you can set up your repo with GitLab CI by adding
+this to your configuration file (src/ontology/oba-odk.yaml):
+
ci:
+ - gitlab-ci
+
+
This will add a file called .gitlab-ci.yml in the root of your repo.
The editors workflow is one of the formal workflows to ensure that the ontology is developed correctly according to ontology engineering principles. There are a few different editors workflows:
+
+
Local editing workflow: Editing the ontology in your local environment by hand, using tools such as Protégé, ROBOT templates or DOSDP patterns.
+
Completely automated data pipeline (GitHub Actions)
+
DROID workflow
+
+
This document only covers the first editing workflow, but more will be added in the future
+
Local editing workflow
+
Workflow requirements:
+
+
git
+
github
+
docker
+
editing tool of choice, e.g. Protégé, your favourite text editor, etc
+
+
1. Create issue
+
Ensure that there is a ticket on your issue tracker that describes the change you are about to make. While this seems optional, this is a very important part of the social contract of building an ontology - no change to the ontology should be performed without a good ticket, describing the motivation and nature of the intended change.
+
2. Update main branch
+
In your local environment (e.g. your laptop), make sure you are on the main (prev. master) branch and ensure that you have all the upstream changes, for example:
+
git checkout master
+git pull
+
+
3. Create feature branch
+
Create a new branch. Per convention, we try to use meaningful branch names such as:
+- issue23removeprocess (where issue 23 is the related issue on GitHub)
+- issue26addcontributor
+- release20210101 (for releases)
+
On your command line, this looks like this:
+
git checkout -b issue23removeprocess
+
+
4. Perform edit
+
Using your editor of choice, perform the intended edit. For example:
+
Protégé
+
+
Open src/ontology/oba-edit.owl in Protégé
+
Make the change
+
Save the file
+
+
TextEdit
+
+
Open src/ontology/oba-edit.owl in TextEdit (or Sublime, Atom, Vim, Nano)
+
Make the change
+
Save the file
+
+
Consider the following when making the edit.
+
+
According to our development philosophy, the only places that should be manually edited are:
+
src/ontology/oba-edit.owl
+
Any ROBOT templates you chose to use (the TSV files only)
+
Any DOSDP data tables you chose to use (the TSV files, and potentially the associated patterns)
+
components (anything in src/ontology/components), see here.
+
+
+
Imports should not be edited (any edits will be flushed out with the next update). However, refreshing imports is a potentially breaking change - and is discussed elsewhere.
+
Changes should usually be small. Adding or changing 1 term is great. Adding or changing 10 related terms is ok. Adding or changing 100 or more terms at once should be considered very carefully.
+
+
4. Check the Git diff
+
This step is very important. Rather than simply trusting your change had the intended effect, we should always use a git diff as a first pass for sanity checking.
+
In our experience, having a visual git client like GitHub Desktop or sourcetree is really helpful for this part. In case you prefer the command line:
+
git status
+git diff
+
+
5. Quality control
+
Now it's time to run your quality control checks. This can either happen locally (5a) or through your continuous integration system (7/5b).
+
5a. Local testing
+
If you chose to run your test locally:
+
sh run.sh make IMP=false test
+
+
This will run the whole set of configured ODK tests on including your change. If you have a complex DOSDP pattern pipeline you may want to add PAT=false to skip the potentially lengthy process of rebuilding the patterns.
+
sh run.sh make IMP=false PAT=false test
+
+
6. Pull request
+
When you are happy with the changes, you commit your changes to your feature branch, push them upstream (to GitHub) and create a pull request. For example:
+
git add NAMEOFCHANGEDFILES
+git commit -m "Added biological process term #12"
+git push -u origin issue23removeprocess
+
+
Then you go to your project on GitHub, and create a new pull request from the branch, for example: https://github.com/INCATools/ontology-development-kit/pulls
+
There is a lot of great advise on how to write pull requests, but at the very least you should:
+- mention the tickets affected: see #23 to link to a related ticket, or fixes #23 if, by merging this pull request, the ticket is fixed. Tickets in the latter case will be closed automatically by GitHub when the pull request is merged.
+- summarise the changes in a few sentences. Consider the reviewer: what would they want to know right away.
+- If the diff is large, provide instructions on how to review the pull request best (sometimes, there are many changed files, but only one important change).
+
7/5b. Continuous Integration Testing
+
If you didn't run and local quality control checks (see 5a), you should have Continuous Integration (CI) set up, for example:
+- Travis
+- GitHub Actions
+
More on how to set this up here. Once the pull request is created, the CI will automatically trigger. If all is fine, it will show up green, otherwise red.
+
8. Community review
+
Once all the automatic tests have passed, it is important to put a second set of eyes on the pull request. Ontologies are inherently social - as in that they represent some kind of community consensus on how a domain is organised conceptually. This seems high brow talk, but it is very important that as an ontology editor, you have your work validated by the community you are trying to serve (e.g. your colleagues, other contributors etc.). In our experience, it is hard to get more than one review on a pull request - two is great. You can set up GitHub branch protection to actually require a review before a pull request can be merged! We recommend this.
+
This step seems daunting to some hopefully under-resourced ontologies, but we recommend to put this high up on your list of priorities - train a colleague, reach out!
+
9. Merge and cleanup
+
When the QC is green and the reviews are in (approvals), it is time to merge the pull request. After the pull request is merged, remember to delete the branch as well (this option will show up as a big button right after you have merged the pull request). If you have not done so, close all the associated tickets fixed by the pull request.
+
10. Changelog (Optional)
+
It is sometimes difficult to keep track of changes made to an ontology. Some ontology teams opt to document changes in a changelog (simply a text file in your repository) so that when release day comes, you know everything you have changed. This is advisable at least for major changes (such as a new release system, a new pattern or template etc.).
We can define custom checks using SPARQL. SPARQL queries define bad modelling patterns (missing labels, misspelt URIs, and many more) in the ontology. If these queries return any results, then the build will fail. Custom checks are designed to be run as part of GitHub Actions Continuous Integration testing, but they can also run locally.
+
Steps to add a constraint violation check:
+
+
Add the SPARQL query in src/sparql. The name of the file should end with -violation.sparql. Please give a name that helps to understand which violation the query wants to check.
+
Add the name of the new file to odk configuration file src/ontology/uberon-odk.yaml:
+
Include the name of the file (without the -violation.sparql part) to the list inside the key custom_sparql_checks that is inside robot_report key.
+
+
If the robot_report or custom_sparql_checks keys are not available, please add this code block to the end of the file.
+
yaml
+ robot_report:
+ release_reports: False
+ fail_on: ERROR
+ use_labels: False
+ custom_profile: True
+ report_on:
+ - edit
+ custom_sparql_checks:
+ - name-of-the-file-check
+3. Update the repository so your new SPARQL check will be included in the QC.
The documentation for OBA is managed in two places (relative to the repository root):
+
+
The docs directory contains all the files that pertain to the content of the documentation (more below)
+
the mkdocs.yaml file contains the documentation config, in particular its navigation bar and theme.
+
+
The documentation is hosted using GitHub pages, on a special branch of the repository (called gh-pages). It is important that this branch is never deleted - it contains all the files GitHub pages needs to render and deploy the site. It is also important to note that the gh-pages branch should never be edited manually. All changes to the docs happen inside the docs directory on the main branch.
+
Editing the docs
+
Changing content
+
All the documentation is contained in the docs directory, and is managed in Markdown. Markdown is a very simple and convenient way to produce text documents with formatting instructions, and is very easy to learn - it is also used, for example, in GitHub issues. This is a normal editing workflow:
+
+
Open the .md file you want to change in an editor of choice (a simple text editor is often best). IMPORTANT: Do not edit any files in the docs/odk-workflows/ directory. These files are managed by the ODK system and will be overwritten when the repository is upgraded! If you wish to change these files, make an issue on the ODK issue tracker.
+
Perform the edit and save the file
+
Commit the file to a branch, and create a pull request as usual.
+
If your development team likes your changes, merge the docs into master branch.
+
Deploy the documentation (see below)
+
+
Deploy the documentation
+
The documentation is not automatically updated from the Markdown, and needs to be deployed deliberately. To do this, perform the following steps:
+
+
In your terminal, navigate to the edit directory of your ontology, e.g.:
+ cd oba/src/ontology
+
Now you are ready to build the docs as follows:
+ sh run.sh make update_docs
+ Mkdocs now sets off to build the site from the markdown pages. You will be asked to
+
Enter your username
+
Enter your password (see here for using GitHub access tokens instead)
+ IMPORTANT: Using password based authentication will be deprecated this year (2021). Make sure you read up on personal access tokens if that happens!
+
+
+
+
If everything was successful, you will see a message similar to this one:
+
INFO - Your documentation should shortly be available at: https://obophenotype.github.io/bio-attribute-ontology/
+3. Just to double check, you can now navigate to your documentation pages (usually https://obophenotype.github.io/bio-attribute-ontology/).
+ Just make sure you give GitHub 2-5 minutes to build the pages!
The release workflow recommended by the ODK is based on GitHub releases and works as follows:
+
+
Run a release with the ODK
+
Review the release
+
Merge to main branch
+
Create a GitHub release
+
+
These steps are outlined in detail in the following.
+
Run a release with the ODK
+
Preparation:
+
+
Ensure that all your pull requests are merged into your main (master) branch
+
Make sure that all changes to master are committed to GitHub (git status should say that there are no modified files)
+
Locally make sure you have the latest changes from master (git pull)
+
Checkout a new branch (e.g. git checkout -b release-2021-01-01)
+
You may or may not want to refresh your imports as part of your release strategy (see here)
+
Make sure you have the latest ODK installed by running docker pull obolibrary/odkfull
+
+
To actually run the release, you:
+
+
Open a command line terminal window and navigate to the src/ontology directory (cd oba/src/ontology)
+
Run release pipeline:sh run.sh make prepare_release -B. Note that for some ontologies, this process can take up to 90 minutes - especially if there are large ontologies you depend on, like PRO or CHEBI.
+
If everything went well, you should see the following output on your machine: Release files are now in ../.. - now you should commit, push and make a release on your git hosting site such as GitHub or GitLab.
+
+
This will create all the specified release targets (OBO, OWL, JSON, and the variants, ont-full and ont-base) and copy them into your release directory (the top level of your repo).
+
Review the release
+
+
(Optional) Rough check. This step is frequently skipped, but for the more paranoid among us (like the author of this doc), this is a 3 minute additional effort for some peace of mind. Open the main release (oba.owl) in you favourite development environment (i.e. Protégé) and eyeball the hierarchy. We recommend two simple checks:
+
Does the very top level of the hierarchy look ok? This means that all new terms have been imported/updated correctly.
+
Does at least one change that you know should be in this release appear? For example, a new class. This means that the release was actually based on the recent edit file.
+
+
+
Commit your changes to the branch and make a pull request
+
In your GitHub pull request, review the following three files in detail (based on our experience):
+
oba.obo - this reflects a useful subset of the whole ontology (everything that can be covered by OBO format). OBO format has that speaking for it: it is very easy to review!
+
oba-base.owl - this reflects the asserted axioms in your ontology that you have actually edited.
+
Ideally also take a look at oba-full.owl, which may reveal interesting new inferences you did not know about. Note that the diff of this file is sometimes quite large.
+
+
+
Like with every pull request, we recommend to always employ a second set of eyes when reviewing a PR!
+
+
Merge the main branch
+
Once your CI checks have passed, and your reviews are completed, you can now merge the branch into your main branch (don't forget to delete the branch afterwards - a big button will appear after the merge is finished).
+
Create a GitHub release
+
+
Go to your releases page on GitHub by navigating to your repository, and then clicking on releases (usually on the right, for example: https://github.com/obophenotype/bio-attribute-ontology/releases). Then click "Draft new release"
+
As the tag version you need to choose the date on which your ontologies were build. You can find this, for example, by looking at the oba.obo file and check the data-version: property. The date needs to be prefixed with a v, so, for example v2020-02-06.
+
You can write whatever you want in the release title, but we typically write the date again. The description underneath should contain a concise list of changes or term additions.
+
Click "Publish release". Done.
+
+
Debugging typical ontology release problems
+
Problems with memory
+
When you are dealing with large ontologies, you need a lot of memory. When you see error messages relating to large ontologies such as CHEBI, PRO, NCBITAXON, or Uberon, you should think of memory first, see here.
+
Problems when using OBO format based tools
+
Sometimes you will get cryptic error messages when using legacy tools using OBO format, such as the ontology release tool (OORT), which is also available as part of the ODK docker container. In these cases, you need to track down what axiom or annotation actually caused the breakdown. In our experience (in about 60% of the cases) the problem lies with duplicate annotations (def, comment) which are illegal in OBO. Here is an example recipe of how to deal with such a problem:
+
+
If you get a message like make: *** [cl.Makefile:84: oort] Error 255 you might have a OORT error.
+
To debug this, in your terminal enter sh run.sh make IMP=false PAT=false oort -B (assuming you are already in the ontology folder in your directory)
+
This should show you where the error is in the log (eg multiple different definitions)
+WARNING: THE FIX BELOW IS NOT IDEAL, YOU SHOULD ALWAYS TRY TO FIX UPSTREAM IF POSSIBLE
+
Open oba-edit.owl in Protégé and find the offending term and delete all offending issue (e.g. delete ALL definition, if the problem was "multiple def tags not allowed") and save.
+*While this is not idea, as it will remove all definitions from that term, it will be added back again when the term is fixed in the ontology it was imported from and added back in.
+
Rerun sh run.sh make IMP=false PAT=false oort -B and if it all passes, commit your changes to a branch and make a pull request as usual.
Your ODK repositories configuration is managed in src/ontology/oba-odk.yaml. The ODK Project Configuration Schema defines all possible parameters that can be used in this config YAML. Once you have made your changes, you can run the following to apply your changes to the repository:
+
sh run.sh make update_repo
+
+
There are a large number of options that can be set to configure your ODK, but we will only discuss a few of them here.
+
NOTE for Windows users:
+
You may get a cryptic failure such as Set Illegal Option - if the update script located in src/scripts/update_repo.sh
+was saved using Windows Line endings. These need to change to unix line endings. In Notepad++, for example, you can
+click on Edit->EOL Conversion->Unix LF to change this.
+
Managing imports
+
You can use the update repository workflow described on this page to perform the following operations to your imports:
+
+
Add a new import
+
Modify an existing import
+
Remove an import you no longer want
+
Customise an import
+
+
We will discuss all these workflows in the following.
+
Add new import
+
To add a new import, you first edit your odk config as described above, adding an id to the product list in the import_group section (for the sake of this example, we assume you already import RO, and your goal is to also import GO):
+
import_group:
+ products:
+ - id: ro
+ - id: go
+
+
Note: our ODK file should only have one import_group which can contain multiple imports (in the products section). Next, you run the update repo workflow to apply these changes. Note that by default, this module is going to be a SLME Bottom module, see here. To change that or customise your module, see section "Customise an import". To finalise the addition of your import, perform the following steps:
+
+
Add an import statement to your src/ontology/oba-edit.owl file. We suggest to do this using a text editor, by simply copying an existing import declaration and renaming it to the new ontology import, for example as follows:
+ ...
+ Ontology(<http://purl.obolibrary.org/obo/oba.owl>
+ Import(<http://purl.obolibrary.org/obo/oba/imports/ro_import.owl>)
+ Import(<http://purl.obolibrary.org/obo/oba/imports/go_import.owl>)
+ ...
+
Add your imports redirect to your catalog file src/ontology/catalog-v001.xml, for example:
+ <uri name="http://purl.obolibrary.org/obo/oba/imports/go_import.owl" uri="imports/go_import.owl"/>
in your catalog, tools like robot or Protégé will recognize the statement
+in the catalog file to redirect the URL http://purl.obolibrary.org/obo/oba/imports/go_import.owl
+to the local file imports/go_import.owl (which is in your src/ontology directory).
+
Modify an existing import
+
If you simply wish to refresh your import in light of new terms, see here. If you wish to change the type of your module see section "Customise an import".
+
Remove an existing import
+
To remove an existing import, perform the following steps:
+
+
remove the import declaration from your src/ontology/oba-edit.owl.
+
remove the id from your src/ontology/oba-odk.yaml, eg. - id: go from the list of products in the import_group.
A ROBOT filter module is, essentially, importing all external terms declared by your ontology (see here on how to declare external terms to be imported). Note that the filter module does
+not consider terms/annotations from namespaces other than the base-namespace of the ontology itself. For example, in the
+example of GO above, only annotations / axioms related to the GO base IRI (http://purl.obolibrary.org/obo/GO_) would be considered. This
+behaviour can be changed by adding additional base IRIs as follows:
If you wish to customise your import entirely, you can specify your own ROBOT command to do so. To do that, add the following to your repo config (src/ontology/oba-odk.yaml):
Now feel free to change this goal to do whatever you wish it to do! It probably makes some sense (albeit not being a strict necessity), to leave most of the goal instead and replace only:
When running sh run.sh make update_repo, a new file src/ontology/components/mycomp.owl will
+be created which you can edit as you see fit. Typical ways to edit:
+
+
Using a ROBOT template to generate the component (see below)
+
Manually curating the component separately with Protégé or any other editor
+
Providing a components/mycomp.owl: make target in src/ontology/oba.Makefile
+and provide a custom command to generate the component
+
WARNING: Note that the custom rule to generate the component MUST NOT depend on any other ODK-generated file such as seed files and the like (see issue).
+
+
+
Providing an additional attribute for the component in src/ontology/oba-odk.yaml, source,
+to specify that this component should simply be downloaded from somewhere on the web.
+
+
Adding a new component based on a ROBOT template
+
Since ODK 1.3.2, it is possible to simply link a ROBOT template to a component without having to specify any of the import logic. In order to add a new component that is connected to one or more template files, follow these steps:
+
+
Open src/ontology/oba-odk.yaml.
+
Make sure that use_templates: TRUE is set in the global project options. You should also make sure that use_context: TRUE is set in case you are using prefixes in your templates that are not known to robot, such as OMOP:, CPONT: and more. All non-standard prefixes you are using should be added to config/context.json.
+
Add another component to the products section.
+
To activate this component to be template-driven, simply say: use_template: TRUE. This will create an empty template for you in the templates directory, which will automatically be processed when recreating the component (e.g. run.bat make recreate-mycomp).
+
If you want to use more than one component, use the templates field to add as many template names as you wish. ODK will look for them in the src/templates directory.
+
Advanced: If you want to provide additional processing options, you can use the template_options field. This should be a string with option from robot template. One typical example for additional options you may want to provide is --add-prefixes config/context.json to ensure the prefix map of your context is provided to robot, see above.
Release file are the file that are considered part of the official ontology release and to be used by the community. A detailed description of the release artefacts can be found here.
+
Imports
+
Imports are subsets of external ontologies that contain terms and axioms you would like to re-use in your ontology. These are considered "external", like dependencies in software development, and are not included in your "base" product, which is the release artefact which contains only those axioms that you personally maintain.
Components, in contrast to imports, are considered full members of the ontology. This means that any axiom in a component is also included in the ontology base - which means it is considered native to the ontology. While this sounds complicated, consider this: conceptually, no component should be part of more than one ontology. If that seems to be the case, we are most likely talking about an import. Components are often not needed for ontologies, but there are some use cases:
+
+
There is an automated process that generates and re-generates a part of the ontology
+
A part of the ontology is managed in ROBOT templates
+
The expressivity of the component is higher than the format of the edit file. For example, people still choose to manage their ontology in OBO format (they should not) missing out on a lot of owl features. They may choose to manage logic that is beyond OBO in a specific OWL component.
One of the most frequent problems with running the ODK for the first time is failure because of lack of memory. This can look like a Java OutOfMemory exception,
+but more often than not it will appear as something like an Error 137. There are two places you need to consider to set your memory:
+
+
Your src/ontology/run.sh (or run.bat) file. You can set the memory in there by adding
+robot_java_args: '-Xmx8G' to your src/ontology/oba-odk.yaml file, see for example here.
+
Set your docker memory. By default, it should be about 10-20% more than your robot_java_args variable. You can manage your memory settings
+by right-clicking on the docker whale in your system bar-->Preferences-->Resources-->Advanced, see picture below.
This page discusses how to update the contents of your imports, like adding or removing terms. If you are looking to customise imports, like changing the module type, see here.
+
Importing a new term
+
Note: some ontologies now use a merged-import system to manage dynamic imports, for these please follow instructions in the section title "Using the Base Module approach".
+
Importing a new term is split into two sub-phases:
+
+
Declaring the terms to be imported
+
Refreshing imports dynamically
+
+
Declaring terms to be imported
+
There are three ways to declare terms that are to be imported from an external ontology. Choose the appropriate one for your particular scenario (all three can be used in parallel if need be):
+
+
Protégé-based declaration
+
Using term files
+
Using the custom import template
+
+
Protégé-based declaration
+
This workflow is to be avoided, but may be appropriate if the editor does not have access to the ODK docker container.
+This approach also applies to ontologies that use base module import approach.
+
+
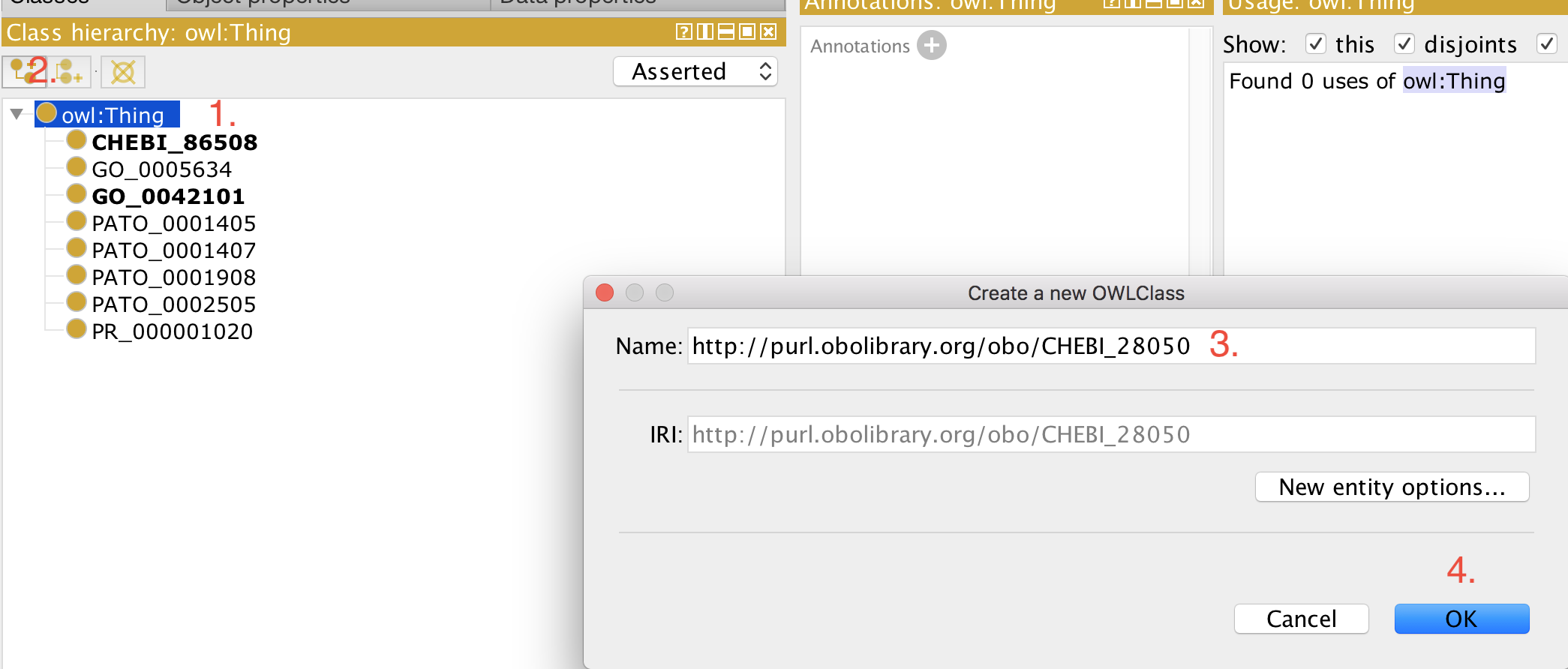
Open your ontology (edit file) in Protégé (5.5+).
+
Select 'owl:Thing'
+
Add a new class as usual.
+
Paste the full iri in the 'Name:' field, for example, http://purl.obolibrary.org/obo/CHEBI_50906.
+
Click 'OK'
+
+
+
Now you can use this term for example to construct logical definitions. The next time the imports are refreshed (see how to refresh here), the metadata (labels, definitions, etc.) for this term are imported from the respective external source ontology and becomes visible in your ontology.
+
Using term files
+
Every import has, by default a term file associated with it, which can be found in the imports directory. For example, if you have a GO import in src/ontology/go_import.owl, you will also have an associated term file src/ontology/go_terms.txt. You can add terms in there simply as a list:
You prefer to manage all your imported terms in a single file (rather than multiple files like in the "Using term files" workflow above).
+
You wish to augment your imported ontologies with additional information. This requires a cautionary discussion.
+
+
To enable this workflow, you add the following to your ODK config file (src/ontology/oba-odk.yaml), and update the repository:
+
use_custom_import_module: TRUE
+
+
Now you can manage your imported terms directly in the custom external terms template, which is located at src/templates/external_import.owl. Note that this file is a ROBOT template, and can, in principle, be extended to include any axioms you like. Before extending the template, however, read the following carefully.
+
The main purpose of the custom import template is to enable the management off all terms to be imported in a centralised place. To enable that, you do not have to do anything other than maintaining the template. So if you, say currently import APOLLO_SV:00000480, and you wish to import APOLLO_SV:00000532, you simply add a row like this:
+
ID Entity Type
+ID TYPE
+APOLLO_SV:00000480 owl:Class
+APOLLO_SV:00000532 owl:Class
+
+
When the imports are refreshed see imports refresh workflow, the term(s) will simply be imported from the configured ontologies.
+
Now, if you wish to extend the Makefile (which is beyond these instructions) and add, say, synonyms to the imported terms, you can do that, but you need to (a) preserve the ID and ENTITY columns and (b) ensure that the ROBOT template is valid otherwise, see here.
+
WARNING. Note that doing this is a widespread antipattern (see related issue). You should not change the axioms of terms that do not belong into your ontology unless necessary - such changes should always be pushed into the ontology where they belong. However, since people are doing it, whether the OBO Foundry likes it or not, at least using the custom imports module as described here localises the changes to a single simple template and ensures that none of the annotations added this way are merged into the base file.
+
Refresh imports
+
If you want to refresh the import yourself (this may be necessary to pass the travis tests), and you have the ODK installed, you can do the following (using go as an example):
+
First, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
+
cd src/ontology
+
+
Then, you regenerate the import that will now include any new terms you have added. Note: You must have docker installed.
+
sh run.sh make PAT=false imports/go_import.owl -B
+
+
Since ODK 1.2.27, it is also possible to simply run the following, which is the same as the above:
+
sh run.sh make refresh-go
+
+
Note that in case you changed the defaults, you need to add IMP=true and/or MIR=true to the command below:
+
sh run.sh make IMP=true MIR=true PAT=false imports/go_import.owl -B
+
+
If you wish to skip refreshing the mirror, i.e. skip downloading the latest version of the source ontology for your import (e.g. go.owl for your go import) you can set MIR=false instead, which will do the exact same thing as the above, but is easier to remember:
+
sh run.sh make IMP=true MIR=false PAT=false imports/go_import.owl -B
+
+
Using the Base Module approach
+
Since ODK 1.2.31, we support an entirely new approach to generate modules: Using base files.
+The idea is to only import axioms from ontologies that actually belong to it.
+A base file is a subset of the ontology that only contains those axioms that nominally
+belong there. In other words, the base file does not contain any axioms that belong
+to another ontology. An example would be this:
The base file pipeline is a bit more complex than the normal pipelines, because
+of the logical interactions between the imported ontologies. This is solved by _first
+merging all mirrors into one huge file and then extracting one mega module from it.
+
Example: Let's say we are importing terms from Uberon, GO and RO in our ontologies.
+When we use the base pipelines, we
+
1) First obtain the base (usually by simply downloading it, but there is also an option now to create it with ROBOT)
+2) We merge all base files into one big pile
+3) Then we extract a single module imports/merged_import.owl
+
The first implementation of this pipeline is PATO, see https://github.com/pato-ontology/pato/blob/master/src/ontology/pato-odk.yaml.
+
To check if your ontology uses this method, check src/ontology/oba-odk.yaml to see if use_base_merging: TRUE is declared under import_group
+
If your ontology uses Base Module approach, please use the following steps:
+
First, add the term to be imported to the term file associated with it (see above "Using term files" section if this is not clear to you)
+
Next, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
+
cd src/ontology
+
+
Then refresh imports by running
+
sh run.sh make imports/merged_import.owl
+
+
Note: if your mirrors are updated, you can run sh run.sh make no-mirror-refresh-merged
+
This requires quite a bit of memory on your local machine, so if you encounter an error, it might be a lack of memory on your computer. A solution would be to create a ticket in an issue tracker requesting for the term to be imported, and one of the local devs should pick this up and run the import for you.
+
Lastly, restart Protégé, and the term should be imported in ready to be used.
To add custom components to an ODK repo, please follow the following steps:
+
1) Locate your odk yaml file and open it with your favourite text editor (src/ontology/oba-odk.yaml)
+2) Search if there is already a component section to the yaml file, if not add it accordingly, adding the name of your component:
5) Refresh your repo by running sh run.sh make update_repo - this should create a new file in src/ontology/components.
+6) In your custom makefile (src/ontology/oba.Makefile) add a goal for your custom make file. In this example, the goal is a ROBOT template.
You can find descriptions of the standard ontology engineering workflows (ODK) here.
"},{"location":"cite/","title":"How to cite OBA","text":"
Please cite
Stefancsik R, Balhoff JP, Balk MA, Ball RL, Bello SM, Caron AR, Chesler EJ, de\nSouza V, Gehrke S, Haendel M, Harris LW, Harris NL, Ibrahim A, Koehler S,\nMatentzoglu N, McMurry JA, Mungall CJ, Munoz-Torres MC, Putman T, Robinson P,\nSmedley D, Sollis E, Thessen AE, Vasilevsky N, Walton DO, Osumi-Sutherland D.\nThe Ontology of Biological Attributes (OBA)-computational traits for the life sciences.\nMamm Genome. 2023 Apr.\n
doi:10.1007/s00335-023-09992-1 PMID: 37076585
See also Zenodo.
"},{"location":"contributing/","title":"How to contribute to OBA","text":"
See https://github.com/obophenotype/bio-attribute-ontology/blob/master/CONTRIBUTING.md.
"},{"location":"editors-guide/","title":"Local development workflows with OBA","text":""},{"location":"editors-guide/#edit-files","title":"Edit files","text":"
There are three kinds of files to edit in OBO explained in the following:
The normal OBA edit file (src/ontology/obo-edit.obo)
The OBA SSSOM mappings (src/mappings/*)
The OBA DOSDP pattern files (src/patterns/data/default/*)
"},{"location":"editors-guide/#the-oba-edit-file","title":"The OBA edit file","text":"
As opposed to other ontologies, the OBA edit file (src/ontology/obo-edit.obo) is barely used. Power curators will use the oba-edit.obo file occasionally to edit the class hierarchy, but as per OBA principles, the class hierarchy is mostly created by reasoning. Most of OBA editing happens by editing the DOSDP templates, see below.
"},{"location":"editors-guide/#the-oba-sssom-mappings","title":"The OBA SSSOM mappings","text":"
OBA-VT SSSOM Mapping: The official mappings between OBA and VT. Source of truth is on Google Sheets, not Github.
OBA-EFO SSSOM Mapping: The official mappings between OBA and EFO. Source of truth is on Google Sheets, not Github.
OBA-EFO Excluded Mapping: Terms from EFO that have been reviewed and deemed out of scope for OBA. Source of truth is on Google Sheets, not Github.
OBA-VT Excluded Mapping: Terms from EFO that have been reviewed and deemed out of scope for OBA. Source of truth is on Google Sheets, not Github.
"},{"location":"editors-guide/#the-oba-dosdp-patterns","title":"The OBA DOSDP patterns","text":"
All OBA DOSDP data tables can be found here.
DOSDP tables are the main way to edit OBA. You can edit the DOSDP TSV files using a regular text editor or a spreadsheet editor.
The main rule is, make sure to review the diff before making a pull request - the diff should only show the things you have actually changed.
Update the data required for the alignment: sh run.sh make prepare_oba_alignment -B. This will take a while, as a lot of ontologies are downloaded and syncronised.
Start jupyter in your local environment
Open src/scripts/oba_alignment.ipynb in your Jupyter environment and run all over night.
While the above is running, read everything in the notebook carefully to get a sense what the notebook is doing. The methods section can be skipped during the first read through, but it will likely be necessary to review these in later stages of the alignment process.
The notebook run will produce the following files:
src/mappings/oba-vt-unreviewed.sssom.tsv: VT mappings identified by pipeline but not reviewed
src/mappings/oba-vt-missed.sssom.tsv: VT mappings identified by looking at OBA IRIs (no need for review)
src/mappings/oba-vt-unmapped.sssom.tsv: VT terms that have not been mapped so far (excluding reviewed and candidate mappings)
src/mappings/oba-vt-unreviewed.dosdp.tsv: VT terms with candidate DOSDP pattern fillings.
src/mappings/oba-efo-unreviewed.sssom.tsv: see above vt analog
src/mappings/oba-efo-unmapped.sssom.tsv: see above vt analog
src/mappings/oba-efo-unreviewed.dosdp.tsv: see above vt analog
Follow the steps in the preparing alignment workflow
The central pieces for the EFO alignment, if of interest, can be found in the section starting with OBA-EFO Alignment in src/scripts/oba_alignment.ipynb.
Review src/mappings/oba-efo-unreviewed.sssom.tsv. These are the new mapping suggestions as determined by the mapping pipeline. Review mappings 1 x 1 and copy them into the official EFO-OBA SSSOM mapping curated on Google Sheets.
Review src/mappings/oba-efo-unreviewed.dosdp.tsv. This is the hardest part. The table only provides a handful of suggests on how to map the label using DOSDP. You will have to go through the table subject_id by subject_id and identify the correct corresponding DOSDP pattern tables. Important: when you create an ID (defined_class column DOSDP table) for an EFO-sourced class, you have to add a respective mapping to the official EFO-OBA SSSOM mapping curated on Google Sheets.
Optional: Review src/mappings/oba-efo-unmapped.sssom.tsv to figure out what to do about entirely unmapped EFO terms. These may need some careful planning and adjustments of the alignment code.
Follow the steps in the preparing alignment workflow
The central pieces for the EFO alignment, if of interest, can be found in the section starting with OBA-VT Alignment in src/scripts/oba_alignment.ipynb.
Review src/mappings/oba-vt-missed.sssom.tsv. This should ideally be empty - these are mappings that have not been factored into the official oba-vt mappings yet, but have the VT-style IRI (OBA:VT0010108) which suggests that the class was derived from the respective VT id. Add all mappings in oba-vt-missed.sssom.tsv to the official VT-OBA SSSOM mapping curated on Google Sheets.
Review src/mappings/oba-vt-unreviewed.sssom.tsv. These are the new mapping suggestions as determined by the mapping pipeline. Review mappings 1 x 1 and copy them into the official VT-OBA SSSOM mapping curated on Google Sheets.
Review src/mappings/oba-vt-unreviewed.dosdp.tsv. This is the hardest part. The table only provides a handful of suggests on how to map the label using DOSDP. You will have to go through the table subject_id by subject_id and identify the correct corresponding DOSDP pattern tables. Important: when you create an ID (defined_class column DOSDP table) for a VT-sourced class, you add a special IRI that looks like OBA:VT123. This way, mappings will be curated automatically by the framework and you dont have to add them manually.
Optional: Review src/mappings/oba-vt-unmapped.sssom.tsv to figure out what to do about entirely unmapped VT terms. These may need some careful planning and adjustments of the alignment code.
Go to Google sheet for \"measured in\" annotations and add annotations
Go to cd src/ontology in your terminal
Create a new branch with your favourite tool
Run sh run.sh make sync_templates_google_sheets to sync templates from Google sheets
Convince yourself in your favourite git diff tool (GitHub Desktop!) that the changed tables look as intended!
In your terminal, run sh run.sh make recreate-measured_in
When completed, the file src/ontology/components/measured_in.owl should have been updated. Look at the diff again to convince yourself that the changes look as intended. You may want to open oba-edit.obo in Protege to look at one or two changes!
Make sure you are on your new branch created above and commit changes to branch.
Publish branch (push to GitHub), make pull request, assign reviewer.
Follow the instructions for adding \"measured in\" annotations above, except:
Add the synonyms in this sheet here
Instead of sh run.sh make recreate-measured_in, sh run.sh make recreate-synonyms
"},{"location":"editors-guide/#importing-terms-and-updating-dosdp-patterns","title":"Importing terms and updating DOSDP patterns","text":"
When creating new OBA terms using DOSDP patterns for example the entity-attribute pattern, it may be necessary to import terms from other ontologies like CHEBI or PRO, the PRotein Ontology. However, CHEBI, NCBITAXON and PRO are too large to be managed easily as standard imports. To mitigate this situation, they can be managed as slims which are located here: * NCBITAXON: https://github.com/obophenotype/ncbitaxon/tree/master/subsets * PRO: https://github.com/obophenotype/pro_obo_slim * CHEBI: https://github.com/obophenotype/chebi_obo_slim
Sometimes, a new term you are using in a DOSDP pattern is not yet in a slim. So you will have to refresh the slim first.
LIPID map is currently (03.06.2023) not imported, but curated manually, because https://www.lipidmaps.org/resources/sparql does not work. To update the LIPID maps imports, you have to
Add a LIPID term to https://github.com/obophenotype/bio-attribute-ontology/blob/master/src/templates/external.tsv
When refreshing the imports in the usual way, this TSV file (a ROBOT template) is built in place of a proper LIPID MAPS mirror.
"},{"location":"editors-guide/#refresh-pro-slim","title":"Refresh PRO Slim:","text":"
Note: you will need at least 32 GB RAM for this
git clone https://github.com/obophenotype/pro_obo_slim\ncd pro_obo_slim\ngit checkout -b refresh20230312\n# Add your terms to seed.txt, and then SORT THE FILE and check that there are no duplicated terms.\n# Make sure that DOCKER is running. To set up DOCKER refer to https://oboacademy.github.io/obook/howto/odk-setup/\nsh odk.sh make all\ngit commit -a -m \"refresh slim after adding terms for OBA\"\ngit push --set-upstream origin refresh20230312\n
git clone https://github.com/obophenotype/chebi_obo_slim\ncd chebi_obo_slim\n# Follow the instructions for the PRO slim from here.\n
The full process of refreshing the DOSDP patterns: 1. Check if new PRO / Chebi terms are not in slim, if they are not, add them as described above. 2. Run sh run.sh make IMP=false MIR=false ../patterns/definitions.owl to generate a new pattern ontology component. 3. Run sh run.sh make refresh-merged to import the new terms. 4. Run sh run.sh make IMP=false MIR=false ../patterns/definitions.owl again to generate the labels correctly where new terms are concerned.
"},{"location":"history/","title":"A brief history of OBA","text":"
The following page gives an overview of the history of OBA.
The raw data (ontology metrics) can be found on GitHub.
"},{"location":"oba-gwas-sop/","title":"How to add new GWAS requested trait terms to OBA and EFO?","text":""},{"location":"oba-gwas-sop/#1-check-if-an-appropriate-oba-trait-pattern-already-exists","title":"1. Check if an appropriate OBA trait pattern already exists","text":"
Look into bio-attribute-ontology/src/patterns/dosdp-patterns/ and check if the GWAS trait term would fit into any of the existing patterns. - [ ] If yes, skip to the next step. - [ ] If none of the existing OBA trait patterns look appropriate, then create a new pattern. In some cases, the requested GWAS term may not fit the scope of OBA. In that case, an new EFO term can be created without an equivalent OBA trait term.
"},{"location":"oba-gwas-sop/#2-create-new-oba-terms","title":"2. Create new OBA term(s)","text":"
Create a new github branch for the edits.
Fill in the appropriate DOS-DP template data table to add any new terms to OBA in bio-attribute-ontology/src/patterns/data/default/.
For example, for a trait involving the 'age at which disease manifestations first appear', fill in the table disease_onset.tsv.. Create a unique OBA identifier by using the next available ID from your assigned range.
Also fill in the appropriate columns for the variable fields as specified in the actual DOS-DP yaml template file. For example, in the case of the disease_onset.tsv. table, you must use MONDO disease or disorder terms in the disease column.
NOTE: Keep track of the IDs from your range that you have already assigned.
Create a pull request (PR) with the edits. Request other people to review your PR.
If approved, merge the PR after the review(s) into the 'master' branch.
"},{"location":"oba-gwas-sop/#3-oba-release","title":"3. OBA release","text":"
The newly created trait terms can be imported into EFO from a publicly released version of OBA.
To run the OBA release pipeline, follow the instructions in the document Release Workflow for the Ontology of Biological Attributes (OBA).
"},{"location":"oba-gwas-sop/#4-provide-the-new-oba-terms-to-efo","title":"4. Provide the new OBA terms to EFO","text":"
[ ] Add the newly created OBA term IRI and also all its component term IRIs to oba_terms.txt so that they get included in EFO dynamic imports. By component terms I mean all those terms that are used in the DOS-DP data filler table to compose the OBA term (terms from MONDO, UBERON, PATO, etc.) as specified in the corresponding DOS-DP pattern file.
[ ] This step depends on a new public OBA release.
[ ] You need to accomplish this in an EFO PR.
"},{"location":"oba-release-sop/","title":"Release Workflow for the Ontology of Biological Attributes (OBA)","text":"
Make sure you have the latest ODK installed by running docker:
docker pull obolibrary/odkfull\n
Merge as many open PRs as possible.
Start with a fresh copy of the master branch. For the next steps you can use GitHub Desktop or the command line instructions below.
git pull\n
Create a new branch:
git checkout -b release-202X-XX-XX\n
In a terminal window, start the release pipeline:
sh run.sh make prepare_release_fast\n
NOTE: It is recommended that running the release pipeline is uncoupled from refreshing imports. However, inn case you need to refresh all the imports, you can achieve that by:
sh run.sh make prepare_release -B\n
If everything went all right, you should see message similar to the one below in your terminal window:
... Release files are now in ../.. - now you should commit, push and make a release on your git hosting site such as GitHub or GitLab make[1]: Leaving directory '/work/src/ontology' Please remember to update your ODK image from time to time: https://oboacademy.github.io/obook/howto/odk-update/.
"},{"location":"oba-release-sop/#check-and-package-the-release-artefacts-for-oba","title":"Check and package the release artefacts for OBA","text":"
You should also check in Protege if the new terms you just added look fine.
Open in Protege some of the OBA release artefacts and check for any potential errors. For example, check if there are any unsatisfiable classes in oba.obo.
Create a pull request and get another pair of eyes to review it.
Merge your release-202X-XX-XX branch into the master branch once approved by a reviewer and all the automatic quality control checks passed.
"},{"location":"oba-release-sop/#make-a-release-and-include-all-the-release-files-including-oba-baseowl-and-obaobo-as-binary-files","title":"Make a release and include all the release files (including oba-base.owl and oba.obo) as binary files","text":"
Use the github web interface to create a new OBA release.
There should be 15 recently modified files in the root directory of the local copy of the repo:
oba-base.json
oba-base.obo
oba-base.owl
oba-baseplus.json
oba-baseplus.obo
oba-baseplus.owl
oba-basic.json
oba-basic.obo
oba-basic.owl
oba-full.json
oba-full.obo
oba-full.owl
oba.json
oba.obo
oba.owl
NOTE: GitHub imposes size constraints on repositories. The combined size of the OBA artefacts exceeds the GitHub imposed size limit. For this reason, some of the large release artefact files are not under GitHub version control. However, all the 15 files need to be included in the public release as binary files. For background information on release artefacts, see
OWL, OBO, JSON? Base, simple, full, basic? What should you use, and why?
Release artefacts
Navigate to the 'Releases' page of OBA
Click Draft a new release. Click Chose a tag, and create a new tag based on the date on which your ontologies were build. You can find this, for example, by looking into the oba.obo file and checking the data-version: property. The date needs to be prefixed with a v, so, for example v2022-10-17.
For the title, you can use the date of the ontology build again, for example 2022-10-17 release
Drag and drop the files listed above or manually select them in the binaries box. using the github web user-interface.
"},{"location":"odk-workflows/ContinuousIntegration/","title":"Introduction to Continuous Integration Workflows with ODK","text":"
Historically, most repos have been using Travis CI for continuous integration testing and building, but due to runtime restrictions, we recently switched a lot of our repos to GitHub actions. You can set up your repo with CI by adding this to your configuration file (src/ontology/oba-odk.yaml):
ci:\n - github_actions\n
When updateing your repo, you will notice a new file being added: .github/workflows/qc.yml.
This file contains your CI logic, so if you need to change, or add anything, this is the place!
Alternatively, if your repo is in GitLab instead of GitHub, you can set up your repo with GitLab CI by adding this to your configuration file (src/ontology/oba-odk.yaml):
ci:\n - gitlab-ci\n
This will add a file called .gitlab-ci.yml in the root of your repo.
The editors workflow is one of the formal workflows to ensure that the ontology is developed correctly according to ontology engineering principles. There are a few different editors workflows:
Local editing workflow: Editing the ontology in your local environment by hand, using tools such as Prot\u00e9g\u00e9, ROBOT templates or DOSDP patterns.
Completely automated data pipeline (GitHub Actions)
DROID workflow
This document only covers the first editing workflow, but more will be added in the future
Ensure that there is a ticket on your issue tracker that describes the change you are about to make. While this seems optional, this is a very important part of the social contract of building an ontology - no change to the ontology should be performed without a good ticket, describing the motivation and nature of the intended change.
"},{"location":"odk-workflows/EditorsWorkflow/#2-update-main-branch","title":"2. Update main branch","text":"
In your local environment (e.g. your laptop), make sure you are on the main (prev. master) branch and ensure that you have all the upstream changes, for example:
Create a new branch. Per convention, we try to use meaningful branch names such as: - issue23removeprocess (where issue 23 is the related issue on GitHub) - issue26addcontributor - release20210101 (for releases)
Using your editor of choice, perform the intended edit. For example:
Prot\u00e9g\u00e9
Open src/ontology/oba-edit.owl in Prot\u00e9g\u00e9
Make the change
Save the file
TextEdit
Open src/ontology/oba-edit.owl in TextEdit (or Sublime, Atom, Vim, Nano)
Make the change
Save the file
Consider the following when making the edit.
According to our development philosophy, the only places that should be manually edited are:
src/ontology/oba-edit.owl
Any ROBOT templates you chose to use (the TSV files only)
Any DOSDP data tables you chose to use (the TSV files, and potentially the associated patterns)
components (anything in src/ontology/components), see here.
Imports should not be edited (any edits will be flushed out with the next update). However, refreshing imports is a potentially breaking change - and is discussed elsewhere.
Changes should usually be small. Adding or changing 1 term is great. Adding or changing 10 related terms is ok. Adding or changing 100 or more terms at once should be considered very carefully.
"},{"location":"odk-workflows/EditorsWorkflow/#4-check-the-git-diff","title":"4. Check the Git diff","text":"
This step is very important. Rather than simply trusting your change had the intended effect, we should always use a git diff as a first pass for sanity checking.
In our experience, having a visual git client like GitHub Desktop or sourcetree is really helpful for this part. In case you prefer the command line:
Now it's time to run your quality control checks. This can either happen locally (5a) or through your continuous integration system (7/5b).
"},{"location":"odk-workflows/EditorsWorkflow/#5a-local-testing","title":"5a. Local testing","text":"
If you chose to run your test locally:
sh run.sh make IMP=false test\n
This will run the whole set of configured ODK tests on including your change. If you have a complex DOSDP pattern pipeline you may want to add PAT=false to skip the potentially lengthy process of rebuilding the patterns.
When you are happy with the changes, you commit your changes to your feature branch, push them upstream (to GitHub) and create a pull request. For example:
git add NAMEOFCHANGEDFILES\ngit commit -m \"Added biological process term #12\"\ngit push -u origin issue23removeprocess\n
Then you go to your project on GitHub, and create a new pull request from the branch, for example: https://github.com/INCATools/ontology-development-kit/pulls
There is a lot of great advise on how to write pull requests, but at the very least you should: - mention the tickets affected: see #23 to link to a related ticket, or fixes #23 if, by merging this pull request, the ticket is fixed. Tickets in the latter case will be closed automatically by GitHub when the pull request is merged. - summarise the changes in a few sentences. Consider the reviewer: what would they want to know right away. - If the diff is large, provide instructions on how to review the pull request best (sometimes, there are many changed files, but only one important change).
If you didn't run and local quality control checks (see 5a), you should have Continuous Integration (CI) set up, for example: - Travis - GitHub Actions
More on how to set this up here. Once the pull request is created, the CI will automatically trigger. If all is fine, it will show up green, otherwise red.
"},{"location":"odk-workflows/EditorsWorkflow/#8-community-review","title":"8. Community review","text":"
Once all the automatic tests have passed, it is important to put a second set of eyes on the pull request. Ontologies are inherently social - as in that they represent some kind of community consensus on how a domain is organised conceptually. This seems high brow talk, but it is very important that as an ontology editor, you have your work validated by the community you are trying to serve (e.g. your colleagues, other contributors etc.). In our experience, it is hard to get more than one review on a pull request - two is great. You can set up GitHub branch protection to actually require a review before a pull request can be merged! We recommend this.
This step seems daunting to some hopefully under-resourced ontologies, but we recommend to put this high up on your list of priorities - train a colleague, reach out!
"},{"location":"odk-workflows/EditorsWorkflow/#9-merge-and-cleanup","title":"9. Merge and cleanup","text":"
When the QC is green and the reviews are in (approvals), it is time to merge the pull request. After the pull request is merged, remember to delete the branch as well (this option will show up as a big button right after you have merged the pull request). If you have not done so, close all the associated tickets fixed by the pull request.
It is sometimes difficult to keep track of changes made to an ontology. Some ontology teams opt to document changes in a changelog (simply a text file in your repository) so that when release day comes, you know everything you have changed. This is advisable at least for major changes (such as a new release system, a new pattern or template etc.).
We can define custom checks using SPARQL. SPARQL queries define bad modelling patterns (missing labels, misspelt URIs, and many more) in the ontology. If these queries return any results, then the build will fail. Custom checks are designed to be run as part of GitHub Actions Continuous Integration testing, but they can also run locally.
"},{"location":"odk-workflows/ManageAutomatedTest/#steps-to-add-a-constraint-violation-check","title":"Steps to add a constraint violation check:","text":"
Add the SPARQL query in src/sparql. The name of the file should end with -violation.sparql. Please give a name that helps to understand which violation the query wants to check.
Add the name of the new file to odk configuration file src/ontology/uberon-odk.yaml:
Include the name of the file (without the -violation.sparql part) to the list inside the key custom_sparql_checks that is inside robot_report key.
If the robot_report or custom_sparql_checks keys are not available, please add this code block to the end of the file.
yaml robot_report: release_reports: False fail_on: ERROR use_labels: False custom_profile: True report_on: - edit custom_sparql_checks: - name-of-the-file-check 3. Update the repository so your new SPARQL check will be included in the QC.
sh run.sh make update_repo\n
"},{"location":"odk-workflows/ManageDocumentation/","title":"Updating the Documentation","text":"
The documentation for OBA is managed in two places (relative to the repository root):
The docs directory contains all the files that pertain to the content of the documentation (more below)
the mkdocs.yaml file contains the documentation config, in particular its navigation bar and theme.
The documentation is hosted using GitHub pages, on a special branch of the repository (called gh-pages). It is important that this branch is never deleted - it contains all the files GitHub pages needs to render and deploy the site. It is also important to note that the gh-pages branch should never be edited manually. All changes to the docs happen inside the docs directory on the main branch.
"},{"location":"odk-workflows/ManageDocumentation/#editing-the-docs","title":"Editing the docs","text":""},{"location":"odk-workflows/ManageDocumentation/#changing-content","title":"Changing content","text":"
All the documentation is contained in the docs directory, and is managed in Markdown. Markdown is a very simple and convenient way to produce text documents with formatting instructions, and is very easy to learn - it is also used, for example, in GitHub issues. This is a normal editing workflow:
Open the .md file you want to change in an editor of choice (a simple text editor is often best). IMPORTANT: Do not edit any files in the docs/odk-workflows/ directory. These files are managed by the ODK system and will be overwritten when the repository is upgraded! If you wish to change these files, make an issue on the ODK issue tracker.
Perform the edit and save the file
Commit the file to a branch, and create a pull request as usual.
If your development team likes your changes, merge the docs into master branch.
Deploy the documentation (see below)
"},{"location":"odk-workflows/ManageDocumentation/#deploy-the-documentation","title":"Deploy the documentation","text":"
The documentation is not automatically updated from the Markdown, and needs to be deployed deliberately. To do this, perform the following steps:
In your terminal, navigate to the edit directory of your ontology, e.g.: cd oba/src/ontology
Now you are ready to build the docs as follows: sh run.sh make update_docs Mkdocs now sets off to build the site from the markdown pages. You will be asked to
Enter your username
Enter your password (see here for using GitHub access tokens instead) IMPORTANT: Using password based authentication will be deprecated this year (2021). Make sure you read up on personal access tokens if that happens!
If everything was successful, you will see a message similar to this one:
INFO - Your documentation should shortly be available at: https://obophenotype.github.io/bio-attribute-ontology/ 3. Just to double check, you can now navigate to your documentation pages (usually https://obophenotype.github.io/bio-attribute-ontology/). Just make sure you give GitHub 2-5 minutes to build the pages!
The release workflow recommended by the ODK is based on GitHub releases and works as follows:
Run a release with the ODK
Review the release
Merge to main branch
Create a GitHub release
These steps are outlined in detail in the following.
"},{"location":"odk-workflows/ReleaseWorkflow/#run-a-release-with-the-odk","title":"Run a release with the ODK","text":"
Preparation:
Ensure that all your pull requests are merged into your main (master) branch
Make sure that all changes to master are committed to GitHub (git status should say that there are no modified files)
Locally make sure you have the latest changes from master (git pull)
Checkout a new branch (e.g. git checkout -b release-2021-01-01)
You may or may not want to refresh your imports as part of your release strategy (see here)
Make sure you have the latest ODK installed by running docker pull obolibrary/odkfull
To actually run the release, you:
Open a command line terminal window and navigate to the src/ontology directory (cd oba/src/ontology)
Run release pipeline:sh run.sh make prepare_release -B. Note that for some ontologies, this process can take up to 90 minutes - especially if there are large ontologies you depend on, like PRO or CHEBI.
If everything went well, you should see the following output on your machine: Release files are now in ../.. - now you should commit, push and make a release on your git hosting site such as GitHub or GitLab.
This will create all the specified release targets (OBO, OWL, JSON, and the variants, ont-full and ont-base) and copy them into your release directory (the top level of your repo).
"},{"location":"odk-workflows/ReleaseWorkflow/#review-the-release","title":"Review the release","text":"
(Optional) Rough check. This step is frequently skipped, but for the more paranoid among us (like the author of this doc), this is a 3 minute additional effort for some peace of mind. Open the main release (oba.owl) in you favourite development environment (i.e. Prot\u00e9g\u00e9) and eyeball the hierarchy. We recommend two simple checks:
Does the very top level of the hierarchy look ok? This means that all new terms have been imported/updated correctly.
Does at least one change that you know should be in this release appear? For example, a new class. This means that the release was actually based on the recent edit file.
Commit your changes to the branch and make a pull request
In your GitHub pull request, review the following three files in detail (based on our experience):
oba.obo - this reflects a useful subset of the whole ontology (everything that can be covered by OBO format). OBO format has that speaking for it: it is very easy to review!
oba-base.owl - this reflects the asserted axioms in your ontology that you have actually edited.
Ideally also take a look at oba-full.owl, which may reveal interesting new inferences you did not know about. Note that the diff of this file is sometimes quite large.
Like with every pull request, we recommend to always employ a second set of eyes when reviewing a PR!
"},{"location":"odk-workflows/ReleaseWorkflow/#merge-the-main-branch","title":"Merge the main branch","text":"
Once your CI checks have passed, and your reviews are completed, you can now merge the branch into your main branch (don't forget to delete the branch afterwards - a big button will appear after the merge is finished).
"},{"location":"odk-workflows/ReleaseWorkflow/#create-a-github-release","title":"Create a GitHub release","text":"
Go to your releases page on GitHub by navigating to your repository, and then clicking on releases (usually on the right, for example: https://github.com/obophenotype/bio-attribute-ontology/releases). Then click \"Draft new release\"
As the tag version you need to choose the date on which your ontologies were build. You can find this, for example, by looking at the oba.obo file and check the data-version: property. The date needs to be prefixed with a v, so, for example v2020-02-06.
You can write whatever you want in the release title, but we typically write the date again. The description underneath should contain a concise list of changes or term additions.
Click \"Publish release\". Done.
"},{"location":"odk-workflows/ReleaseWorkflow/#debugging-typical-ontology-release-problems","title":"Debugging typical ontology release problems","text":""},{"location":"odk-workflows/ReleaseWorkflow/#problems-with-memory","title":"Problems with memory","text":"
When you are dealing with large ontologies, you need a lot of memory. When you see error messages relating to large ontologies such as CHEBI, PRO, NCBITAXON, or Uberon, you should think of memory first, see here.
"},{"location":"odk-workflows/ReleaseWorkflow/#problems-when-using-obo-format-based-tools","title":"Problems when using OBO format based tools","text":"
Sometimes you will get cryptic error messages when using legacy tools using OBO format, such as the ontology release tool (OORT), which is also available as part of the ODK docker container. In these cases, you need to track down what axiom or annotation actually caused the breakdown. In our experience (in about 60% of the cases) the problem lies with duplicate annotations (def, comment) which are illegal in OBO. Here is an example recipe of how to deal with such a problem:
If you get a message like make: *** [cl.Makefile:84: oort] Error 255 you might have a OORT error.
To debug this, in your terminal enter sh run.sh make IMP=false PAT=false oort -B (assuming you are already in the ontology folder in your directory)
This should show you where the error is in the log (eg multiple different definitions) WARNING: THE FIX BELOW IS NOT IDEAL, YOU SHOULD ALWAYS TRY TO FIX UPSTREAM IF POSSIBLE
Open oba-edit.owl in Prot\u00e9g\u00e9 and find the offending term and delete all offending issue (e.g. delete ALL definition, if the problem was \"multiple def tags not allowed\") and save. *While this is not idea, as it will remove all definitions from that term, it will be added back again when the term is fixed in the ontology it was imported from and added back in.
Rerun sh run.sh make IMP=false PAT=false oort -B and if it all passes, commit your changes to a branch and make a pull request as usual.
"},{"location":"odk-workflows/RepoManagement/","title":"Managing your ODK repository","text":""},{"location":"odk-workflows/RepoManagement/#updating-your-odk-repository","title":"Updating your ODK repository","text":"
Your ODK repositories configuration is managed in src/ontology/oba-odk.yaml. The ODK Project Configuration Schema defines all possible parameters that can be used in this config YAML. Once you have made your changes, you can run the following to apply your changes to the repository:
sh run.sh make update_repo\n
There are a large number of options that can be set to configure your ODK, but we will only discuss a few of them here.
NOTE for Windows users:
You may get a cryptic failure such as Set Illegal Option - if the update script located in src/scripts/update_repo.sh was saved using Windows Line endings. These need to change to unix line endings. In Notepad++, for example, you can click on Edit->EOL Conversion->Unix LF to change this.
You can use the update repository workflow described on this page to perform the following operations to your imports:
Add a new import
Modify an existing import
Remove an import you no longer want
Customise an import
We will discuss all these workflows in the following.
"},{"location":"odk-workflows/RepoManagement/#add-new-import","title":"Add new import","text":"
To add a new import, you first edit your odk config as described above, adding an id to the product list in the import_group section (for the sake of this example, we assume you already import RO, and your goal is to also import GO):
import_group:\n products:\n - id: ro\n - id: go\n
Note: our ODK file should only have one import_group which can contain multiple imports (in the products section). Next, you run the update repo workflow to apply these changes. Note that by default, this module is going to be a SLME Bottom module, see here. To change that or customise your module, see section \"Customise an import\". To finalise the addition of your import, perform the following steps:
Add an import statement to your src/ontology/oba-edit.owl file. We suggest to do this using a text editor, by simply copying an existing import declaration and renaming it to the new ontology import, for example as follows: ... Ontology(<http://purl.obolibrary.org/obo/oba.owl> Import(<http://purl.obolibrary.org/obo/oba/imports/ro_import.owl>) Import(<http://purl.obolibrary.org/obo/oba/imports/go_import.owl>) ...
Add your imports redirect to your catalog file src/ontology/catalog-v001.xml, for example: <uri name=\"http://purl.obolibrary.org/obo/oba/imports/go_import.owl\" uri=\"imports/go_import.owl\"/>
Test whether everything is in order:
Refresh your import
Open in your Ontology Editor of choice (Protege) and ensure that the expected terms are imported.
Note: The catalog file src/ontology/catalog-v001.xml has one purpose: redirecting imports from URLs to local files. For example, if you have
in your catalog, tools like robot or Prot\u00e9g\u00e9 will recognize the statement in the catalog file to redirect the URL http://purl.obolibrary.org/obo/oba/imports/go_import.owl to the local file imports/go_import.owl (which is in your src/ontology directory).
"},{"location":"odk-workflows/RepoManagement/#modify-an-existing-import","title":"Modify an existing import","text":"
If you simply wish to refresh your import in light of new terms, see here. If you wish to change the type of your module see section \"Customise an import\".
"},{"location":"odk-workflows/RepoManagement/#remove-an-existing-import","title":"Remove an existing import","text":"
To remove an existing import, perform the following steps:
remove the import declaration from your src/ontology/oba-edit.owl.
remove the id from your src/ontology/oba-odk.yaml, eg. - id: go from the list of products in the import_group.
run update repo workflow
delete the associated files manually:
src/imports/go_import.owl
src/imports/go_terms.txt
Remove the respective entry from the src/ontology/catalog-v001.xml file.
"},{"location":"odk-workflows/RepoManagement/#customise-an-import","title":"Customise an import","text":"
By default, an import module extracted from a source ontology will be a SLME module, see here. There are various options to change the default.
The following change to your repo config (src/ontology/oba-odk.yaml) will switch the go import from an SLME module to a simple ROBOT filter module:
A ROBOT filter module is, essentially, importing all external terms declared by your ontology (see here on how to declare external terms to be imported). Note that the filter module does not consider terms/annotations from namespaces other than the base-namespace of the ontology itself. For example, in the example of GO above, only annotations / axioms related to the GO base IRI (http://purl.obolibrary.org/obo/GO_) would be considered. This behaviour can be changed by adding additional base IRIs as follows:
If you wish to customise your import entirely, you can specify your own ROBOT command to do so. To do that, add the following to your repo config (src/ontology/oba-odk.yaml):
Now feel free to change this goal to do whatever you wish it to do! It probably makes some sense (albeit not being a strict necessity), to leave most of the goal instead and replace only:
When running sh run.sh make update_repo, a new file src/ontology/components/mycomp.owl will be created which you can edit as you see fit. Typical ways to edit:
Using a ROBOT template to generate the component (see below)
Manually curating the component separately with Prot\u00e9g\u00e9 or any other editor
Providing a components/mycomp.owl: make target in src/ontology/oba.Makefile and provide a custom command to generate the component
WARNING: Note that the custom rule to generate the component MUST NOT depend on any other ODK-generated file such as seed files and the like (see issue).
Providing an additional attribute for the component in src/ontology/oba-odk.yaml, source, to specify that this component should simply be downloaded from somewhere on the web.
"},{"location":"odk-workflows/RepoManagement/#adding-a-new-component-based-on-a-robot-template","title":"Adding a new component based on a ROBOT template","text":"
Since ODK 1.3.2, it is possible to simply link a ROBOT template to a component without having to specify any of the import logic. In order to add a new component that is connected to one or more template files, follow these steps:
Open src/ontology/oba-odk.yaml.
Make sure that use_templates: TRUE is set in the global project options. You should also make sure that use_context: TRUE is set in case you are using prefixes in your templates that are not known to robot, such as OMOP:, CPONT: and more. All non-standard prefixes you are using should be added to config/context.json.
Add another component to the products section.
To activate this component to be template-driven, simply say: use_template: TRUE. This will create an empty template for you in the templates directory, which will automatically be processed when recreating the component (e.g. run.bat make recreate-mycomp).
If you want to use more than one component, use the templates field to add as many template names as you wish. ODK will look for them in the src/templates directory.
Advanced: If you want to provide additional processing options, you can use the template_options field. This should be a string with option from robot template. One typical example for additional options you may want to provide is --add-prefixes config/context.json to ensure the prefix map of your context is provided to robot, see above.
Release file are the file that are considered part of the official ontology release and to be used by the community. A detailed description of the release artefacts can be found here.
Imports are subsets of external ontologies that contain terms and axioms you would like to re-use in your ontology. These are considered \"external\", like dependencies in software development, and are not included in your \"base\" product, which is the release artefact which contains only those axioms that you personally maintain.
These are the current imports in OBA
Import URL Type ro http://purl.obolibrary.org/obo/ro.owl None chebi https://raw.githubusercontent.com/obophenotype/chebi_obo_slim/main/chebi_slim.owl None goplus http://purl.obolibrary.org/obo/go/go-base.owl None go http://purl.obolibrary.org/obo/go.owl None pato http://purl.obolibrary.org/obo/pato.owl None omo http://purl.obolibrary.org/obo/omo.owl None hp http://purl.obolibrary.org/obo/hp.owl None mondo http://purl.obolibrary.org/obo/mondo.owl None ncbitaxon http://purl.obolibrary.org/obo/ncbitaxon/subsets/taxslim.owl None uberon http://purl.obolibrary.org/obo/uberon.owl None cl http://purl.obolibrary.org/obo/cl.owl None nbo http://purl.obolibrary.org/obo/nbo.owl None pr https://raw.githubusercontent.com/obophenotype/pro_obo_slim/master/pr_slim.owl None so http://purl.obolibrary.org/obo/so.owl None po http://purl.obolibrary.org/obo/po.owl None bfo http://purl.obolibrary.org/obo/bfo.owl None swisslipids http://purl.obolibrary.org/obo/swisslipids.owl None lipidmaps http://purl.obolibrary.org/obo/lipidmaps.owl None"},{"location":"odk-workflows/RepositoryFileStructure/#components","title":"Components","text":"
Components, in contrast to imports, are considered full members of the ontology. This means that any axiom in a component is also included in the ontology base - which means it is considered native to the ontology. While this sounds complicated, consider this: conceptually, no component should be part of more than one ontology. If that seems to be the case, we are most likely talking about an import. Components are often not needed for ontologies, but there are some use cases:
There is an automated process that generates and re-generates a part of the ontology
A part of the ontology is managed in ROBOT templates
The expressivity of the component is higher than the format of the edit file. For example, people still choose to manage their ontology in OBO format (they should not) missing out on a lot of owl features. They may choose to manage logic that is beyond OBO in a specific OWL component.
These are the components in OBA
Filename URL obsoletes.owl None synonyms.owl None"},{"location":"odk-workflows/SettingUpDockerForODK/","title":"Setting up your Docker environment for ODK use","text":"
One of the most frequent problems with running the ODK for the first time is failure because of lack of memory. This can look like a Java OutOfMemory exception, but more often than not it will appear as something like an Error 137. There are two places you need to consider to set your memory:
Your src/ontology/run.sh (or run.bat) file. You can set the memory in there by adding robot_java_args: '-Xmx8G' to your src/ontology/oba-odk.yaml file, see for example here.
Set your docker memory. By default, it should be about 10-20% more than your robot_java_args variable. You can manage your memory settings by right-clicking on the docker whale in your system bar-->Preferences-->Resources-->Advanced, see picture below.
This page discusses how to update the contents of your imports, like adding or removing terms. If you are looking to customise imports, like changing the module type, see here.
"},{"location":"odk-workflows/UpdateImports/#importing-a-new-term","title":"Importing a new term","text":"
Note: some ontologies now use a merged-import system to manage dynamic imports, for these please follow instructions in the section title \"Using the Base Module approach\".
Importing a new term is split into two sub-phases:
Declaring the terms to be imported
Refreshing imports dynamically
"},{"location":"odk-workflows/UpdateImports/#declaring-terms-to-be-imported","title":"Declaring terms to be imported","text":"
There are three ways to declare terms that are to be imported from an external ontology. Choose the appropriate one for your particular scenario (all three can be used in parallel if need be):
This workflow is to be avoided, but may be appropriate if the editor does not have access to the ODK docker container. This approach also applies to ontologies that use base module import approach.
Open your ontology (edit file) in Prot\u00e9g\u00e9 (5.5+).
Select 'owl:Thing'
Add a new class as usual.
Paste the full iri in the 'Name:' field, for example, http://purl.obolibrary.org/obo/CHEBI_50906.
Click 'OK'
Now you can use this term for example to construct logical definitions. The next time the imports are refreshed (see how to refresh here), the metadata (labels, definitions, etc.) for this term are imported from the respective external source ontology and becomes visible in your ontology.
"},{"location":"odk-workflows/UpdateImports/#using-term-files","title":"Using term files","text":"
Every import has, by default a term file associated with it, which can be found in the imports directory. For example, if you have a GO import in src/ontology/go_import.owl, you will also have an associated term file src/ontology/go_terms.txt. You can add terms in there simply as a list:
GO:0008150\nGO:0008151\n
Now you can run the refresh imports workflow) and the two terms will be imported.
"},{"location":"odk-workflows/UpdateImports/#using-the-custom-import-template","title":"Using the custom import template","text":"
This workflow is appropriate if:
You prefer to manage all your imported terms in a single file (rather than multiple files like in the \"Using term files\" workflow above).
You wish to augment your imported ontologies with additional information. This requires a cautionary discussion.
To enable this workflow, you add the following to your ODK config file (src/ontology/oba-odk.yaml), and update the repository:
use_custom_import_module: TRUE\n
Now you can manage your imported terms directly in the custom external terms template, which is located at src/templates/external_import.owl. Note that this file is a ROBOT template, and can, in principle, be extended to include any axioms you like. Before extending the template, however, read the following carefully.
The main purpose of the custom import template is to enable the management off all terms to be imported in a centralised place. To enable that, you do not have to do anything other than maintaining the template. So if you, say currently import APOLLO_SV:00000480, and you wish to import APOLLO_SV:00000532, you simply add a row like this:
ID Entity Type\nID TYPE\nAPOLLO_SV:00000480 owl:Class\nAPOLLO_SV:00000532 owl:Class\n
When the imports are refreshed see imports refresh workflow, the term(s) will simply be imported from the configured ontologies.
Now, if you wish to extend the Makefile (which is beyond these instructions) and add, say, synonyms to the imported terms, you can do that, but you need to (a) preserve the ID and ENTITY columns and (b) ensure that the ROBOT template is valid otherwise, see here.
WARNING. Note that doing this is a widespread antipattern (see related issue). You should not change the axioms of terms that do not belong into your ontology unless necessary - such changes should always be pushed into the ontology where they belong. However, since people are doing it, whether the OBO Foundry likes it or not, at least using the custom imports module as described here localises the changes to a single simple template and ensures that none of the annotations added this way are merged into the base file.
If you want to refresh the import yourself (this may be necessary to pass the travis tests), and you have the ODK installed, you can do the following (using go as an example):
First, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
cd src/ontology\n
Then, you regenerate the import that will now include any new terms you have added. Note: You must have docker installed.
sh run.sh make PAT=false imports/go_import.owl -B\n
Since ODK 1.2.27, it is also possible to simply run the following, which is the same as the above:
sh run.sh make refresh-go\n
Note that in case you changed the defaults, you need to add IMP=true and/or MIR=true to the command below:
sh run.sh make IMP=true MIR=true PAT=false imports/go_import.owl -B\n
If you wish to skip refreshing the mirror, i.e. skip downloading the latest version of the source ontology for your import (e.g. go.owl for your go import) you can set MIR=false instead, which will do the exact same thing as the above, but is easier to remember:
sh run.sh make IMP=true MIR=false PAT=false imports/go_import.owl -B\n
"},{"location":"odk-workflows/UpdateImports/#using-the-base-module-approach","title":"Using the Base Module approach","text":"
Since ODK 1.2.31, we support an entirely new approach to generate modules: Using base files. The idea is to only import axioms from ontologies that actually belong to it. A base file is a subset of the ontology that only contains those axioms that nominally belong there. In other words, the base file does not contain any axioms that belong to another ontology. An example would be this:
The base file pipeline is a bit more complex than the normal pipelines, because of the logical interactions between the imported ontologies. This is solved by _first merging all mirrors into one huge file and then extracting one mega module from it.
Example: Let's say we are importing terms from Uberon, GO and RO in our ontologies. When we use the base pipelines, we
1) First obtain the base (usually by simply downloading it, but there is also an option now to create it with ROBOT) 2) We merge all base files into one big pile 3) Then we extract a single module imports/merged_import.owl
The first implementation of this pipeline is PATO, see https://github.com/pato-ontology/pato/blob/master/src/ontology/pato-odk.yaml.
To check if your ontology uses this method, check src/ontology/oba-odk.yaml to see if use_base_merging: TRUE is declared under import_group
If your ontology uses Base Module approach, please use the following steps:
First, add the term to be imported to the term file associated with it (see above \"Using term files\" section if this is not clear to you)
Next, you navigate in your terminal to the ontology directory (underneath src in your hpo root directory).
cd src/ontology\n
Then refresh imports by running
sh run.sh make imports/merged_import.owl\n
Note: if your mirrors are updated, you can run sh run.sh make no-mirror-refresh-merged
This requires quite a bit of memory on your local machine, so if you encounter an error, it might be a lack of memory on your computer. A solution would be to create a ticket in an issue tracker requesting for the term to be imported, and one of the local devs should pick this up and run the import for you.
Lastly, restart Prot\u00e9g\u00e9, and the term should be imported in ready to be used.
"},{"location":"odk-workflows/components/","title":"Adding components to an ODK repo","text":"
For details on what components are, please see component section of repository file structure document.
To add custom components to an ODK repo, please follow the following steps:
1) Locate your odk yaml file and open it with your favourite text editor (src/ontology/oba-odk.yaml) 2) Search if there is already a component section to the yaml file, if not add it accordingly, adding the name of your component:
5) Refresh your repo by running sh run.sh make update_repo - this should create a new file in src/ontology/components. 6) In your custom makefile (src/ontology/oba.Makefile) add a goal for your custom make file. In this example, the goal is a ROBOT template.